
The Attention Layer of LLMs: Because Even AI Needs to Pay Attention! 🎯


Attention is All You Need (Literally!)
Ever been in a conversation where you completely zoned out and then responded with something totally unrelated? Yeah, LLMs without an attention mechanism are like that—just spewing random words with no real understanding. 🤦♂️
Just like humans need to focus to grasp the meaning of a conversation, LLMs need an attention layer to predict the next word (or letter) in a way that actually makes sense. Without it, they'd just generate text as if they had a bad case of selective hearing! 🎧🙉
How Did Attention Even Become a Thing? 🤔
Before the attention mechanism was introduced, LLMs relied on word embeddings to determine word similarity and make predictions. Think of embeddings as a bridge between human-readable words and machine-friendly numbers. They allowed models to perform mathematical operations like cosine similarity to find connections between words.
But there was a big problem: ambiguity. 🚨
For example, take the word bank—it could mean a riverbank or a financial institution. If an LLM only relied on similarity techniques, it wouldn't know which bank you're talking about. Context was missing. And without context, the AI would be about as reliable as autocorrect on a bad day. 😅
This problem led to the introduction of the attention layer, first introduced in the groundbreaking paper Attention Is All You Need. This mechanism allowed LLMs to determine context dynamically, making word embeddings more contextualized rather than just generic word vectors.
Types of Attention Models 🧠✨
There are two main types of attention models:
Self-Attention Model
Multi-Head Attention Model
1️⃣ Self-Attention: The Lone Thinker
Self-attention focuses on a single input sentence and predicts the next word based on that one sentence alone. It works well for short contexts but can struggle with more complex, multi-sentence structures.
2️⃣ Multi-Head Attention: The Team Player
As the name suggests, this model processes multiple self-attention layers in parallel, making a more informed decision. The result? Better contextual understanding, especially when dealing with rich datasets. 🏆
The more heads, the more perspectives, the better the output. It's like having multiple advisors instead of relying on just one opinion! 💡
Understanding Self-Attention with an Example 🎯
Consider these two sentences:
The bank of the river.
Money in the bank.
The word bank means two entirely different things in these sentences. A basic similarity model would struggle, but self-attention fixes this by assigning different weights to bank based on the surrounding words.
The Math Behind It 🧮
To a computer, words are vectors. Imagine moving bank closer to river in one context and closer to money in another. Let's call them BANK_1 and BANK_2.
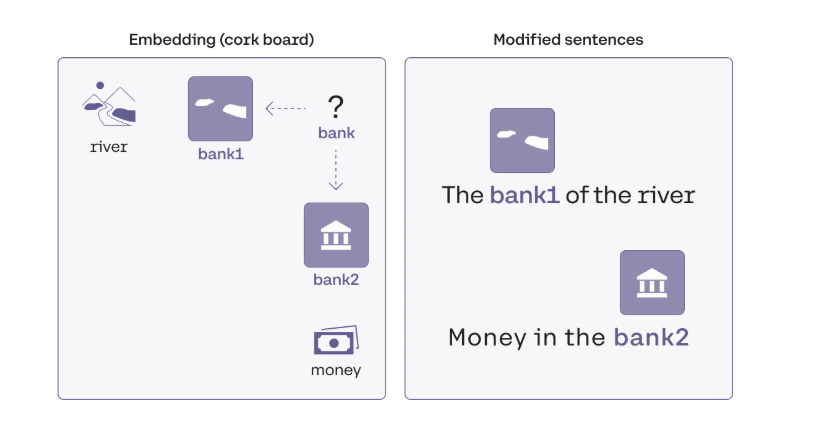
We represent this mathematically as:
BANK_1 = 0.9 × river + 0.1 × bank
BANK_2 = 0.8 × money + 0.2 × bank
Given the coordinates:
River: [0,5]
Money: [8,0]
Bank: [6,6]
We compute:
BANK_1 = [5.4, 5.9]
BANK_2 = [6.4, 6.8]
When plotted, BANK_1 aligns with river and BANK_2 aligns with money, helping the model distinguish their meanings. 🎯
But how does the model know to prioritize river and money over irrelevant words like the, of, and in? Simple: similarity scores! Words with higher similarity scores get more weight, allowing the model to filter out unimportant words. 🤓
Checkout below math if you want to understand how did we get above equation with only river and money as important terms.
The Math Behind how to get river and money as the relevant words 🧮
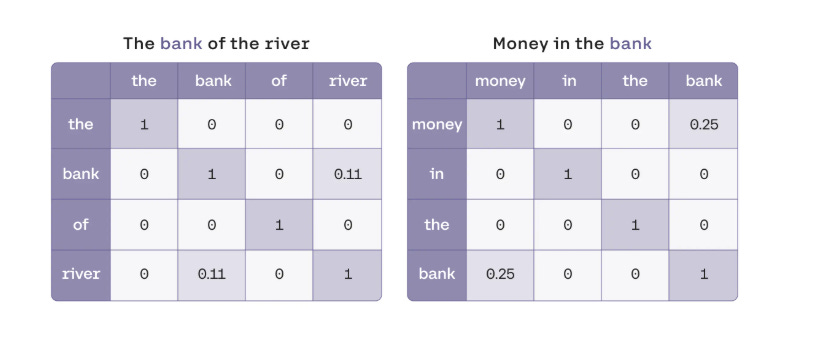
We get the following matrix of similarity.
Now let's follow an exercise
From matrix 1 we get:
the = the
bank = bank + 0.11 river
of = of
river = 0.11 bank + river
Similarly, from matrix 2 we have
money = money + 0.25 bank
in = in
the = the
bank = 0.25 money + bank
So we can see that
BANK_1 = bank + 0.11 river
BANK_2 = 0.25 money + bank
Let's make sum of coefficients 1 by dividing them with the sum of coefficients (guys it's simple component math)
So we get
BANK_1 = 0.9 bank + 0.1 river
BANK_2 = 0.8 bank + 0.2 money
Hence like this we got the above equations for BANK_1 and BANK_2 using similarity score.
Multi-Head Attention: The Power of Parallel Thinking 🔥
While self-attention is great, multi-head attention takes it up a notch by applying multiple self-attention mechanisms simultaneously. Instead of analyzing just one aspect of a sentence, the model learns from multiple perspectives at once. 🧠💥
Why Multi-Head Attention is Superior 🚀
✅ Different heads focus on different parts of the input, capturing diverse relationships.
✅ Prevents over-reliance on specific tokens, ensuring a more balanced understanding.
✅ Provides more robustness by reducing single-point failures. ✅ Encourages learning of general patterns instead of memorizing specific details.
In simpler terms, self-attention is like a single detective solving a case. Multi-head attention? It's an entire team of detectives working together, each focusing on different clues to crack the mystery. 🕵️♂️🔎
Conclusion: Why Should You Care? 🤷♂️
Understanding the attention mechanism is crucial to grasp how LLMs generate human-like responses. Without attention layers, AI-generated text would be riddled with context errors, much like a bad predictive text engine.
So next time you see an LLM responding with spot-on context, just remember—attention is not just all you need, it's all AI needs too! 😉🤖
Stay tuned for more detailed versions of this later where we will decode its interesting research paper :)