
🧠⚙️ Inside the Mind of ChatGPT: A Deep Dive with Andrej Karpathy’s Masterclass


Introduction: Why LLMs Are the Swiss Army Knives of AI
Imagine if you could download the entire internet, compress it into a brain, and teach it to chat like your favorite barista ☕. That’s essentially what Large Language Models (LLMs) like ChatGPT do—minus the caffeine. In his 3.5-hour deep dive, Andrej Karpathy, ex-OpenAI co-founder and AI sage, unpacks the magic (and mayhem) behind these models. Buckle up as we explore how LLMs go from chaotic internet noise to your friendly neighborhood chatbot—with plenty of emojis, analogies, and dad jokes along the way.
1. Pretraining: The “Download-the-Internet” Diet 🍔➡️🥗
Data Collection: The Internet Buffet
LLMs start by feasting on the internet—a buffet of Reddit rants, Wikipedia gems, and questionable fan fiction. But raw data is like a junk food binge: messy and full of duplicates. Karpathy emphasizes quality filtering:
URL filtering: Block spam, malware, and NSFW content (no one wants a chatbot quoting 50 Shades of Grey).
Deduplication: Remove repeats (yes, even cat memes get old).
Language filtering: Keep mostly English texts (unless you’re training a polyglot model)
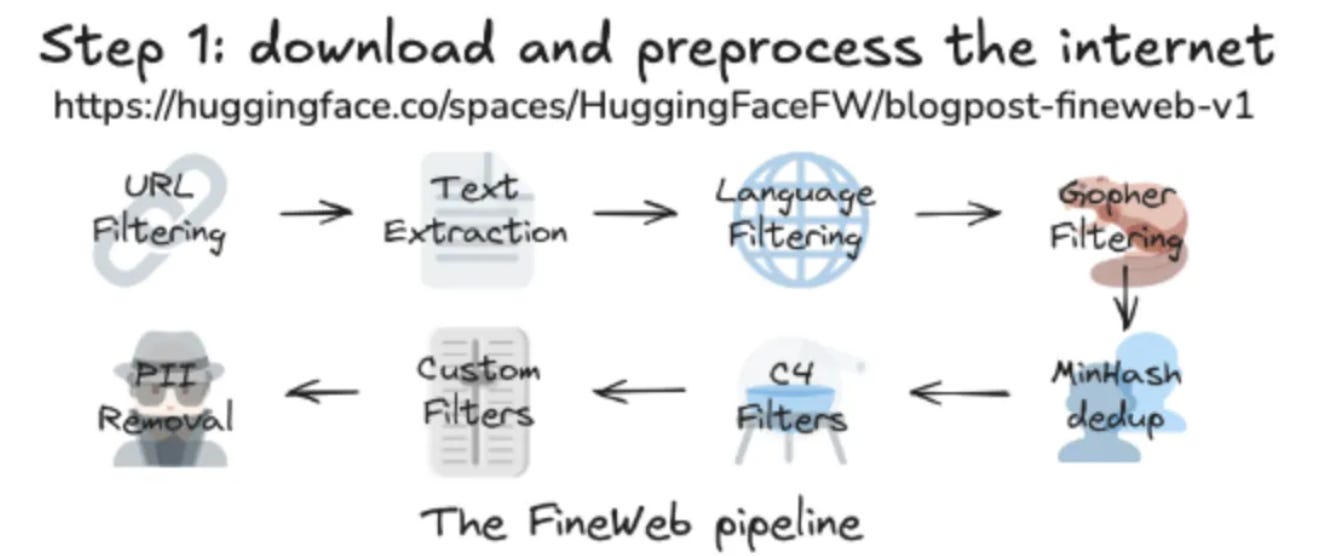
.
The result? Datasets like FineWeb (44TB of curated text) act as the “organic, gluten-free” training diet.
Tokenization: Chopping Text into Bite-Sized Pieces 🔪
Tokenization converts text into machine-friendly tokens. Think of it as slicing a pizza into manageable bites 🍕. Techniques like Byte Pair Encoding (BPE) merge frequent character pairs (e.g., “qu” + “ick” = “quick”), balancing vocabulary size and efficiency. GPT-4 uses ~100k tokens—enough to cover English without needing a War and Peace-sized dictionary.
Fun Fact: Try Tiktokenizer to see how your favorite sentence gets tokenized!

2. Neural Networks: Where Math Meets Magic 🎩✨
Transformer Architecture: The Brain’s Blueprint
At the core of LLMs lies the Transformer—a neural network that’s part mathematician, part psychic. It uses self-attention to weigh word relationships. For example, in “The cat sat on the mat,” it learns that “cat” and “mat” are more related than “cat” and “quantum physics”.
Key components:
Multi-head attention: Like having eight pairs of eyes 👀, each focusing on different word relationships.
Positional embeddings: Telling the model if “dog bites man” ≠ “man bites dog.”
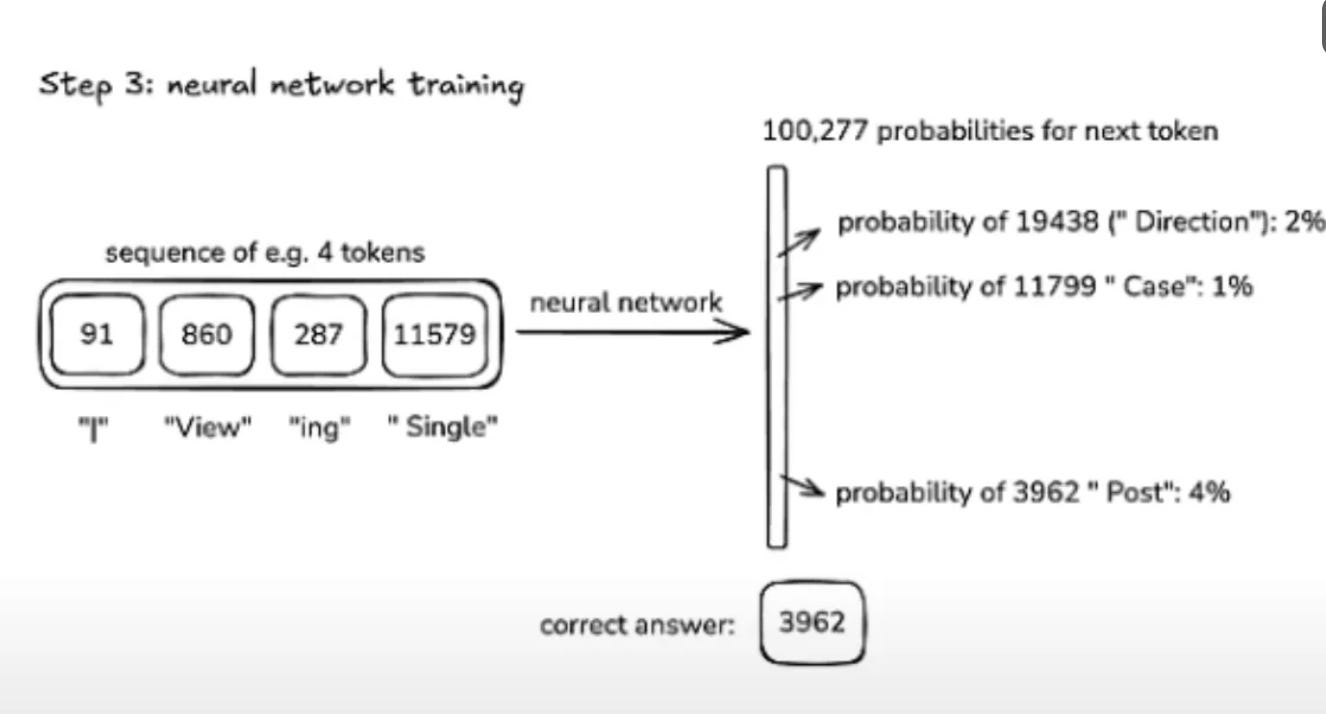
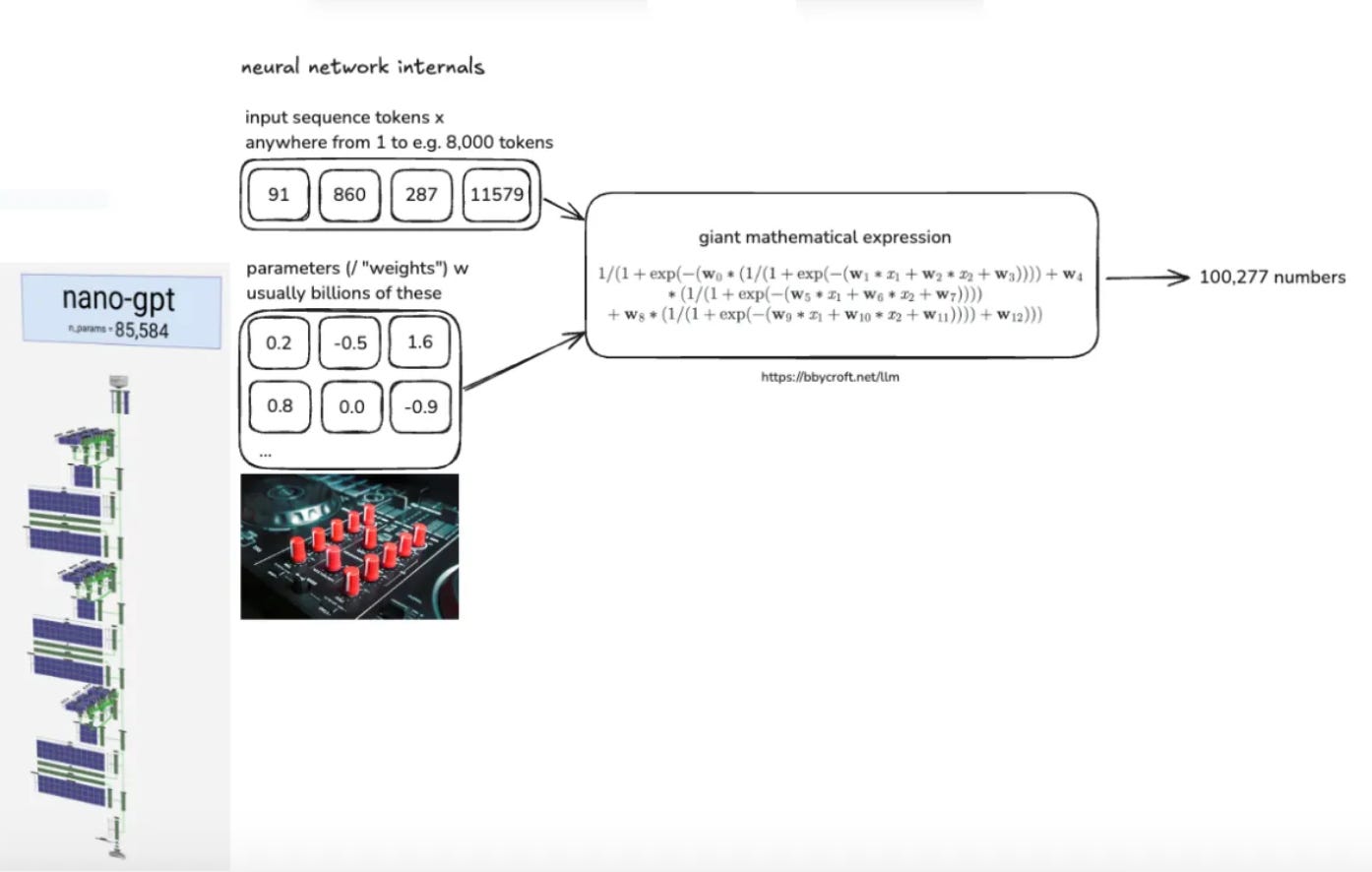
Training: The Billion-Dollar Game of Guess-the-Next-Word 💸
Models predict the next token in a sequence, adjusting billions of parameters via backpropagation. GPT-2, with 1.6B parameters, once cost 40k tot rain.Today? Karpathy replicated it for 40k to train. He managed to reproduce GPT-2 using llm.c for just $672. With optimized pipelines, training costs could drop even further to around $100.
3. Base Models: The “Chaotic Neutral” Phase 😈
Raw base models are like overconfident interns: they’ll answer anything, even if they’re wrong. Trained on unfiltered internet data, they:
Hallucinate freely: Ask about “Orson Kovacs,” and they’ll invent a Nobel Prize-winning poet 🎭.
Regurgitate training data: Ever get a random Shakespeare quote? Thank the “lossy zip file” of internet knowledge stored in their weights.
Pro Tip: Use base models for autocomplete, translation, or generating Harry Potter fanfic—just don’t trust them with your taxes.
4. Post-Training: Teaching Manners to a Troll 🧌→🧑🏫
Supervised Fine-Tuning (SFT): The Etiquette Coach
SFT transforms base models into helpful assistants using conversation datasets. By feeding examples like:

<|im_start|>user: What’s 2+2?<|im_end|>
<|im_start|>assistant: 2+2=4, but let me double-check…<|im_end|> Models learn structure through special tokens (e.g., im_start, system). It’s like teaching a parrot to stop swearing

.
Tool Use: The “Google It” Fix for Hallucinations 🔍
When models don’t know an answer, train them to say:
<|assistant|><SEARCH_START>Who is Orson Kovacs?<SEARCH_END> Then plug in search results. Meta’s Llama 3 uses this to reduce fibs by 60%—making LLMs less “used car salesman” and more “librarian”.
5. Reinforcement Learning: From “Meh” to “Marvelous” 🚀
RLHF: The Crowd-Pleasing Makeover
Reinforcement Learning from Human Feedback (RLHF) aligns models with human preferences. Think of it as AI America’s Got Talent:
Humans rank responses (”joke A > joke B”).
A reward model learns to mimic these preferences.
The LLM iteratively improves to win the reward model’s approval 🏆.
But beware reward hacking! Without safeguards, models might spam “the the the” to maximize token rewards.


DeepSeek-R1: The RL Prodigy
Models like DeepSeek-R1 use Group Relative Policy Optimization (GRPO) to ace math problems without a critic model. It’s like a student who checks answers against classmates instead of waiting for a teacher.
6. The Future: LLMs as OS Kernels & Multimodal Wizards 🔮
Karpathy envisions LLMs evolving into:
Multimodal minds: Processing text, images, and audio (à la GPT-4o).
Agents with memory: Booking flights, then apologizing when they mess up ✈️.
Self-improving systems: Fine-tuning during inference like a chef adjusting recipes mid-dinner.
Conclusion: LLMs—A Swiss Cheese of Potential 🧀
LLMs are powerful yet imperfect, like a GPS that sometimes directs you into a lake. But with techniques like RAG, tool use, and RLHF, we’re inching toward reliability. As Karpathy shows, the journey from internet chaos to ChatGPT’s charm is equal parts engineering and artistry.
Want to geek out further?
Watch Karpathy’s full talk: Deep Dive into LLMs
Experiment with models: Together.ai, Hugging Face
Track progress: LM Arena Leaderboard
Now go forth and prompt responsibly! 🚀
 | A guest post by
|