GPT‑4o Image Generation: Ghibli‑fying the World with AI Artistry


1. A Quick Trip Down Memory Lane 📜
OpenAI’s journey in image generation began with the original DALL‑E, which used a transformer-based approach to generate images from text. The evolution continued with DALL‑E 2 and DALL‑E 3, which improved image quality and coherence. Then came GPT‑4o ("o" for omni), a model that not only generates text and audio but also creates images using the same unified architecture. Imagine a single brain that can write, sing, and paint all at once—it’s the Swiss Army knife of AI! 🔧🎨

2. The Omni Approach: Unified Multimodality 🎨
GPT‑4o treats every kind of data—text, images, and even sound—as sequences of tokens. This means that whether you’re chatting, listening, or looking at pictures, the model processes everything in one common “language.” In essence, it predicts not only the next word but also the next image token, unifying all modalities into one seamless experience.
How It Works: Two Key Stages
Autoregressive Token Generation:
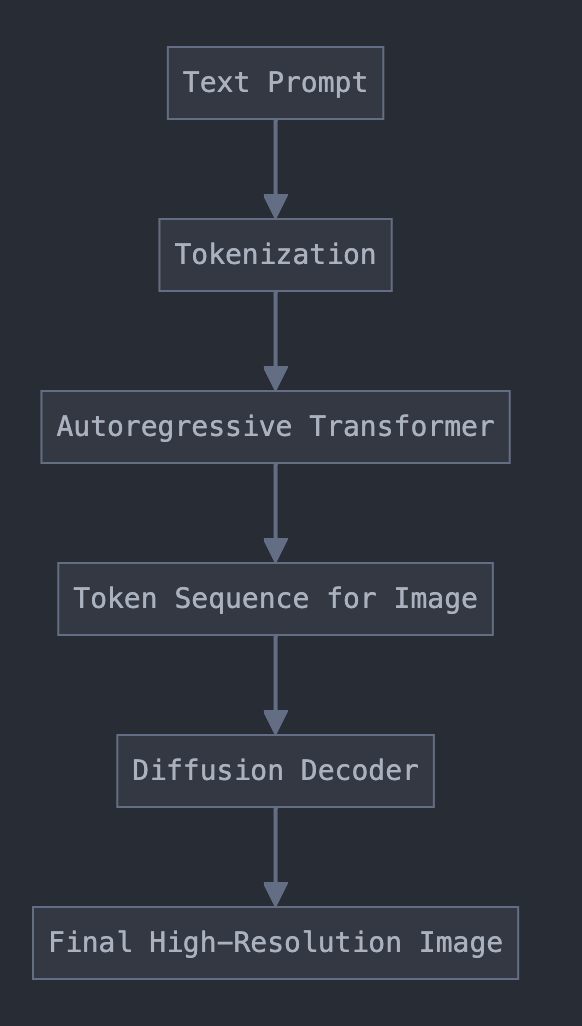
The model first generates a sequence of tokens that represent the target image. Think of it as writing a secret recipe where each “ingredient” (or token) contributes to the final visual flavor.Diffusion-Based Decoding:
Next, these tokens are fed into a diffusion decoder, which gradually “denoises” an initial noisy canvas into a clear, high-resolution image. Picture starting with a fuzzy sketch and then watching the details sharpen step by step—voilà, art emerges!
3. Under the Hood: The Technical Blueprint 🔍
Autoregressive Modeling for Image Tokens
Tokenization:
Images are first compressed using a learned encoder (similar to a VQ‑VAE) into a discrete sequence of tokens. This is like converting a full-color photo into a compact recipe of numbers and symbols.Transformer Magic:
The autoregressive transformer then predicts the next token based on previously generated tokens. It’s similar to predicting the next word in a sentence—but here, each “word” helps form a part of the image!
Diffusion Decoding: Turning Tokens into Pixels
Once the token sequence is ready, a diffusion decoder kicks in:
Initial Noisy Image:
Start with a canvas filled with random noise.Iterative Refinement:
Through a series of denoising steps, the model uses the token information to gradually refine the image, restoring structure and detail until the final photorealistic output appears.
A simplified diagram to illustrate the process:
Binding and Text Rendering
One of GPT‑4o’s standout features is its ability to render text within images accurately. By “binding” the properties of objects (including embedded text) to their correct spatial locations, the model overcomes one of the biggest challenges in AI image generation. In other words, it’s not just splashing pixels randomly—it’s precisely aligning every detail, much like a master calligrapher! ✍️
4. Cross-Modal Transfer: From Text to Image 🔄🖼️
Now, let’s get into the nitty-gritty of how GPT‑4o transfers information across modalities.
Unified Representation: One Token to Rule Them All
Every input—whether text or image—is broken down into tokens, forming a universal language for the model. When you provide a text prompt (say, “a dreamy Ghibli landscape”), GPT‑4o tokenizes your words and maps them into a high-dimensional space where they share a common representation with image tokens.
Cross-Modal Attention and Alignment
Token Embedding:
Text tokens are embedded into a shared space where, during training, images are also converted into tokens using a learned encoder.Cross-Modal Attention:
The transformer uses cross-modal attention layers to let text tokens “talk” to image tokens. It’s like having bilingual translators ensuring that every descriptive detail (“sunny,” “meadow,” “whimsical”) finds its corresponding visual element.Alignment Learning:
Exposed to millions of image–text pairs during training, the model learns the precise mapping between words and visual features. So when you request “a sunny meadow with whimsical creatures,” GPT‑4o retrieves and aligns the learned visual cues accordingly.
The Two-Stage Process Revisited
Autoregressive Generation:
The model generates an ordered sequence of tokens that encode the structure of the desired image.Diffusion Decoding:
This token sequence is then refined through a diffusion process that denoises and brings out the final visual details.
Analogy:
Imagine writing a recipe for a cake (your text prompt). First, you list the ingredients and steps (tokenization and transformer reasoning). Then, the chef (the autoregressive generator) assembles the ingredients in the correct order. Finally, the cake is baked and decorated (diffusion decoding), turning your written recipe into a delectable masterpiece! 🎂✨
5. Editing Your Photo into Ghibli Style: A Multimodal Makeover 🎨✨
One of the coolest features of GPT‑4o is its ability to take an input image (say, your favorite selfie) and transform it into a Studio Ghibli-inspired work of art using a simple prompt like “convert this image into ghibli style.” Here’s how the magic happens under the hood:
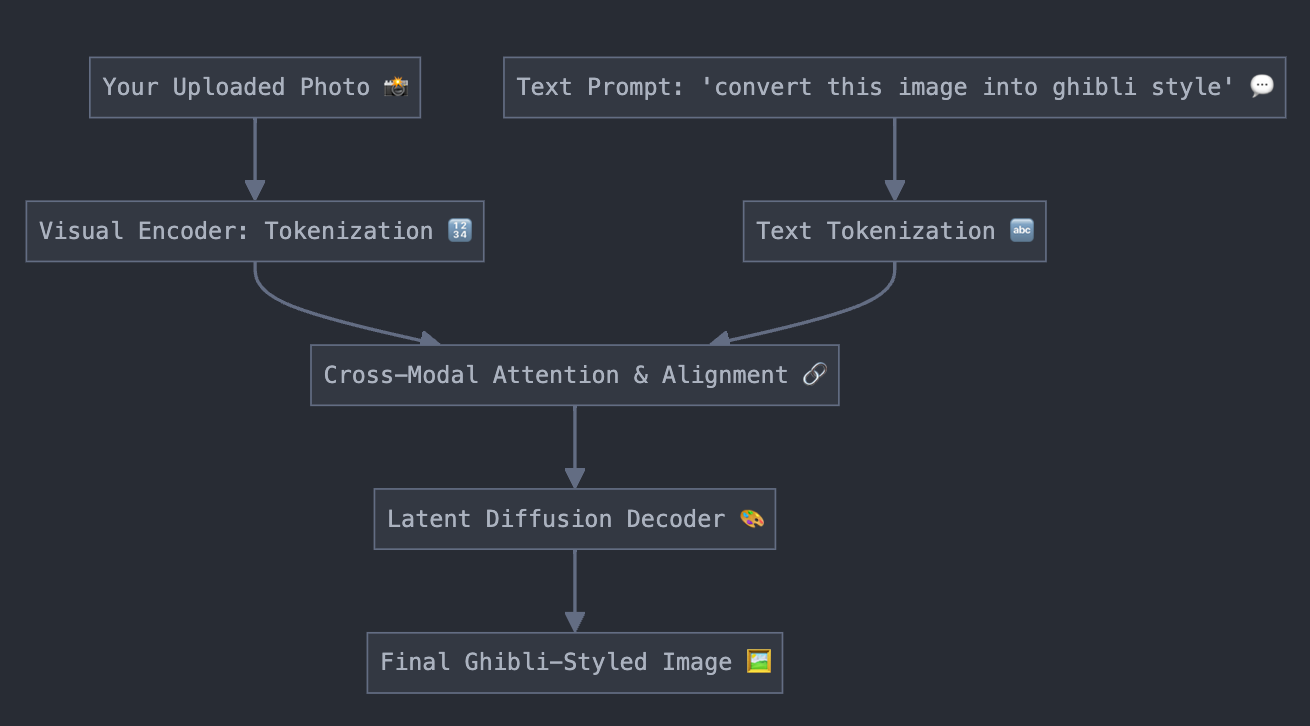
Step 1: Image Ingestion & Tokenization
When you upload your photo, GPT‑4o first passes it through a visual encoder that compresses the image into a sequence of latent tokens. Think of this step as turning your photo into a secret “visual language”—a compact representation that captures all the essential details (colors, shapes, textures) of your image. 📸➡️🔢
Step 2: Prompt Processing & Cross-Modal Alignment
Simultaneously, the text prompt "convert this image into ghibli style" is tokenized into its own sequence. Thanks to the unified multimodal design, the model now has both your image tokens and text tokens in a shared latent space. Cross-modal attention layers then act like bilingual translators, aligning the descriptive power of the prompt with the visual details of your photo. In simple terms, GPT‑4o figures out which parts of your image should be “sprinkled” with that whimsical Ghibli magic! ✨🗣️🖼️
Step 3: Latent Transformation via Diffusion Decoding
With both inputs aligned, the model applies a diffusion-based decoding process:
Iterative Refinement:
The system starts with a noisy version of the image’s latent representation. Step by step, it refines this representation—infusing it with the stylistic cues learned during training. This includes adjusting color palettes, softening edges, and adding hand-drawn, anime-like textures reminiscent of Studio Ghibli.Preserving Identity:
While the Ghibli style transforms the mood and aesthetics, the model carefully preserves key details (like facial features) so the final image still looks like you—just with a delightful animated twist!
A simplified diagram to illustrate this transformation:
Step 4: Output & Fine-Tuning
After the diffusion process completes its iterative denoising, the model decodes the refined latent tokens into a high-resolution image. The output is a stylized version of your original photo that captures the signature warmth, whimsy, and artistic flair of Studio Ghibli. And thanks to continuous fine-tuning and reinforcement learning from human feedback (RLHF), the system keeps improving its ability to maintain both artistic style and personal identity.
6. Safety, Fine-Tuning, and the Ghibli Hype 🔒✨
Safety First
GPT‑4o employs a robust safety stack:
Prompt Blocking & Output Filtering:
Ensures that harmful content is caught before it becomes part of the generated output.Metadata Tagging:
Every image is embedded with C2PA metadata to certify its AI origin, making it easier to track and verify.
Reinforcement Learning from Human Feedback (RLHF)
Post-training, GPT‑4o is fine-tuned using RLHF. Human trainers provide feedback to adjust and refine outputs—ensuring that even the wildest prompts (like turning a selfie into a Studio Ghibli fantasy) are executed with both creativity and technical precision.
The Ghibli Image Hype Explained
So why the buzz over Ghibli‑style images? GPT‑4o’s enhanced ability to generate detailed, coherent images—especially with accurate text rendering and object binding—has sparked a wave of creative outputs. Users can now effortlessly generate whimsical, visually captivating images that resonate with the iconic charm of Studio Ghibli films. It’s like watching your dreams come to life, one token at a time! 🌸🎥

7. References
OpenAI. “Introducing 4o Image Generation.”
OpenAI. “Addendum to GPT‑4o System Card: Native image generation.”
Nichol, A., Dhariwal, P., et al. “GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models.”
Zhang, L., et al. “ScImage: How Good Are Multimodal Large Language Models at Scientific Text-to-Image Generation?”
Zhu, D., et al. “MiniGPT‑4: Enhancing Vision-Language Understanding with Advanced Large Language Models.”
8. Interesting Use cases