
AI Workflows vs. Agents: Understanding the Landscape for Better AI Systems

Navigating the terminology around advanced AI systems can be challenging. Two terms frequently used, sometimes interchangeably, are "AI Workflows" and "AI Agents." While related, they represent distinct approaches to leveraging LLMs for complex tasks. Understanding this distinction is vital for designing, building, and deploying effective AI solutions.
We'll explore different structured approaches (Workflows) and contrast them with more dynamic, autonomous systems (Agents), helping you determine the right strategy for your goals.
(This post is part of a larger series exploring AI agents. Check out the other parts linked below!)
Table of Contents
Defining the Terms: Workflow vs. Agent
Strategic Considerations: When to Choose Which
The Role of Frameworks: Accelerators and Abstractions
The Core Component: The Augmented LLM
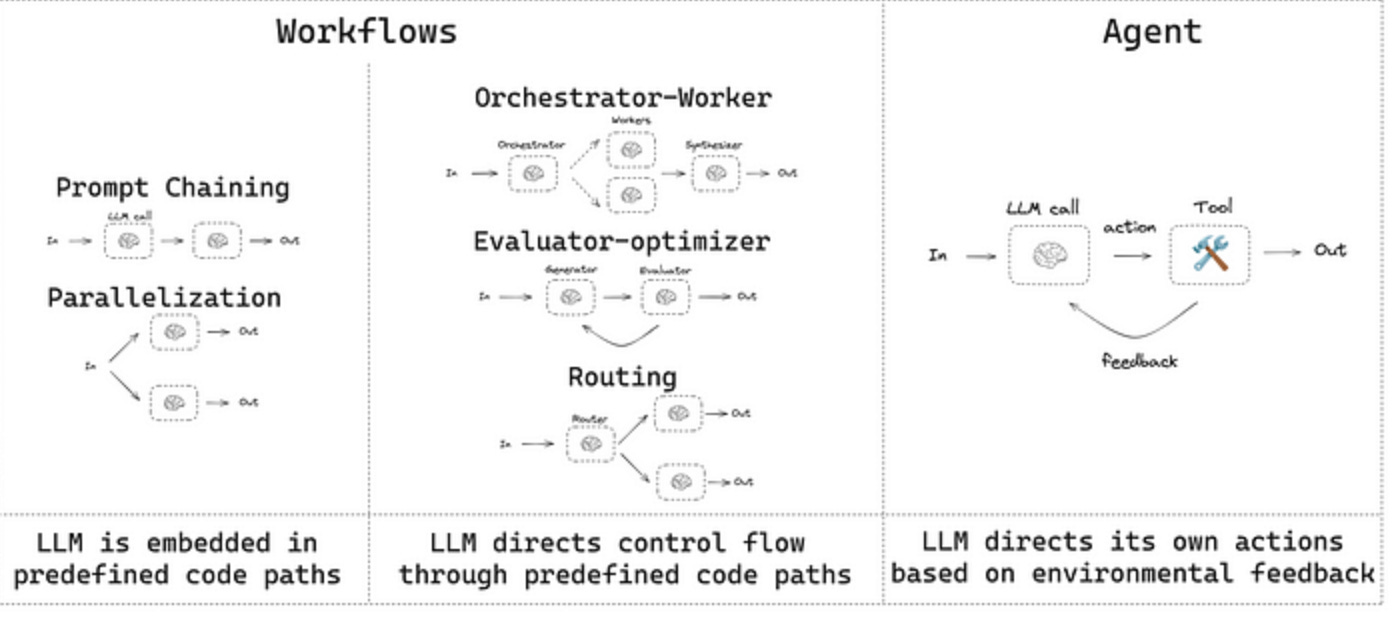
Common AI Workflow Patterns Explained
5.1 Prompt Chaining: The Sequential Path
5.2 Parallelization: Handling Tasks Concurrently
5.3 Routing: Intelligent Task Distribution
5.4 Orchestrator-Worker: Dynamic Task Delegation
5.5 Evaluator-Optimizer: Iterative Refinement Loops
Understanding AI Agents: Dynamic Action and Control
Combining Forces: Integrating Workflows and Agents
Conclusion: Building Appropriately Complex Systems
1. Defining the Terms: Workflow vs. Agent
At their core, both involve using LLMs to accomplish multi-step tasks, but the key difference lies in control and dynamism:
AI Workflows: These systems follow predefined paths or structures. The sequence of operations, potential branches, and decision points are largely designed and hardcoded by developers. LLMs might execute specific steps within the workflow (e.g., summarizing text, drafting an email) or even guide the flow between predefined branches based on certain conditions.
Analogy: Think of a sophisticated automated assembly line. Each station performs a specific task in a set sequence, possibly with checks that might reroute an item, but the overall process map is fixed. The LLM is like a highly skilled worker or a quality control check at specific stations.
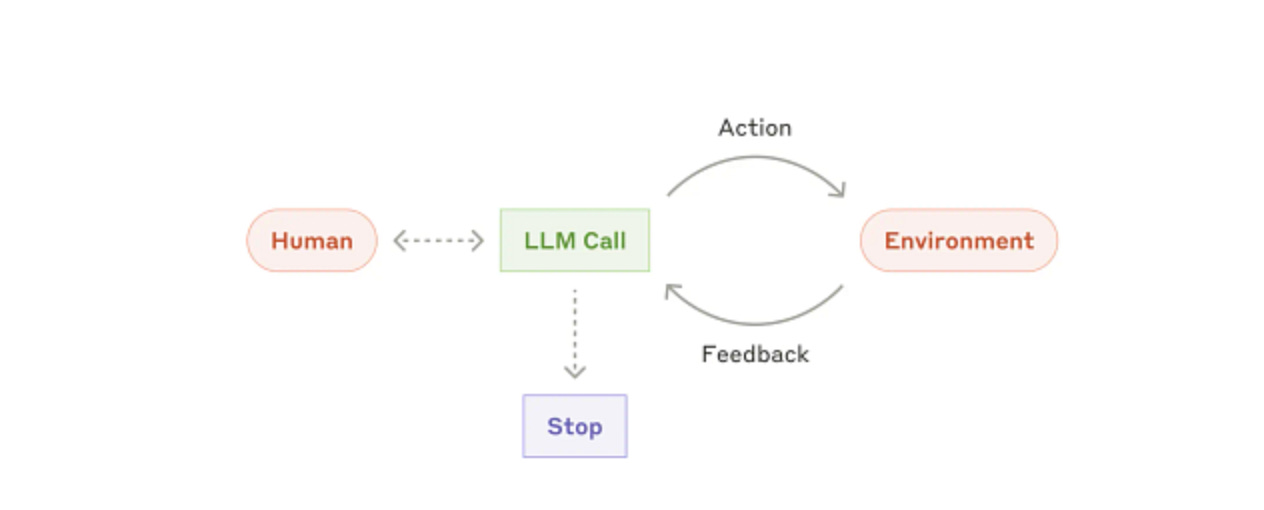
AI Agents: These systems are characterized by dynamic decision-making. The LLM itself determines the next action based on the current situation, its goals, and the tools available to it. It operates in a loop, observing its environment (including feedback from previous actions), reasoning about the next step, and taking action (often by using a tool or API).
Analogy: Consider a skilled detective investigating a case. They don't follow a rigid script. Based on clues found (observation), they decide whether to interview a witness, search a location, or analyze forensic data (action/tool use), constantly adapting their strategy based on new information. The LLM is the detective, driving the investigation.

Credits: Langchain
The LLM's role shifts from being a component within a defined structure (Workflow) to being the driver of the process (Agent).
2. Strategic Considerations: When to Choose Which
The most sophisticated solution isn't always the best. Choosing between a workflow and an agent involves trade-offs:
Start Simple: Begin with the least complex approach that meets the need. Often, optimizing a single prompt with good context or implementing a simple workflow is sufficient.
Predictability vs. Flexibility: Workflows offer higher predictability and control, making them easier to debug and manage. Agents provide greater flexibility to handle unforeseen situations or open-ended tasks where the path isn't known in advance.
Complexity, Latency & Cost: Agents typically involve more LLM calls and intricate state management, leading to higher latency, operational costs, and development complexity compared to structured workflows. Ensure the benefits of an agent's autonomy justify these costs.
Trust & Reliability: Agents require a degree of trust in the LLM's decision-making. Workflows, being more constrained, are often perceived as more reliable for mission-critical processes where deviation is undesirable.
Reserve agentic systems for problems demanding high flexibility, where the steps are unpredictable, and where the value derived from autonomous decision-making outweighs the inherent costs and complexities.
3. The Role of Frameworks: Accelerators and Abstractions
Frameworks (like Langhraph, LlamaIndex, AutoGen, etc.) provide tools and abstractions that can significantly accelerate the development of both workflows and agents. They handle common tasks like LLM interaction, state management, tool definition, and parsing.
However, they introduce layers of abstraction. While helpful for rapid prototyping, it's crucial to understand what the framework does under the hood. Relying heavily on a framework without grasping its internal mechanics can lead to challenging debugging sessions and unexpected behavior. It’s often beneficial to understand the fundamental principles by interacting directly with LLM APIs before adopting complex framework components.
4. The Core Component: The Augmented LLM
Regardless of whether building a workflow or an agent, the foundation is typically an Augmented LLM. This refers to an LLM enhanced with capabilities beyond simple text generation:
Tool Use: Ability to interact with external systems via APIs or functions (e.g., search the web, query a database, execute code).
Retrieval: Accessing and incorporating information from external knowledge bases or documents.
Memory: Maintaining context and information across multiple steps or interactions.
Modern LLMs are increasingly capable of leveraging these augmentations effectively, forming the core intelligence for both structured and dynamic AI systems.
Okay, let's dive deeper into the technical aspects of AI Workflow patterns and AI Agents.
5. Common AI Workflow Patterns: A Technical Deep Dive
While the conceptual overview is useful, understanding the technical underpinnings and challenges of these workflow patterns is crucial for successful implementation.
5.1 Prompt Chaining: Sequential Execution Mechanics
This pattern involves linking LLM calls or processing steps sequentially. The output state of step N becomes the input state for step N+1.
State Management: The primary technical challenge is managing the state passed between steps. This might involve passing large amounts of text, structured data objects, or intermediate results. In graph-based frameworks (like LangGraph), this state is often explicitly defined and managed within a graph state object. Outside frameworks, manual state passing is required, risking data loss or incorrect formatting between steps.
Error Propagation: A failure or poor-quality output in an early step can significantly degrade the performance of all subsequent steps ("context drift" or error accumulation). Robust implementations require intermediate validation gates. These can range from simple programmatic checks (e.g., regex matching, data type validation) to more complex LLM-based evaluations that assess the quality or relevance of the intermediate output before proceeding. Implementing effective, low-cost gates is key.
Context Window Limits: As the chain progresses, the cumulative context passed forward can grow, potentially exceeding the LLM's context window limit. Strategies like intermediate summarization or selective state passing become necessary for longer chains.
Trade-offs vs. Single Prompt: Chaining allows breaking down complexity and potentially using specialized prompts at each step. However, it incurs higher latency (multiple sequential LLM calls) compared to a single, complex prompt designed to achieve the same outcome, although the latter might suffer from reduced coherence or miss specific instructions more easily.
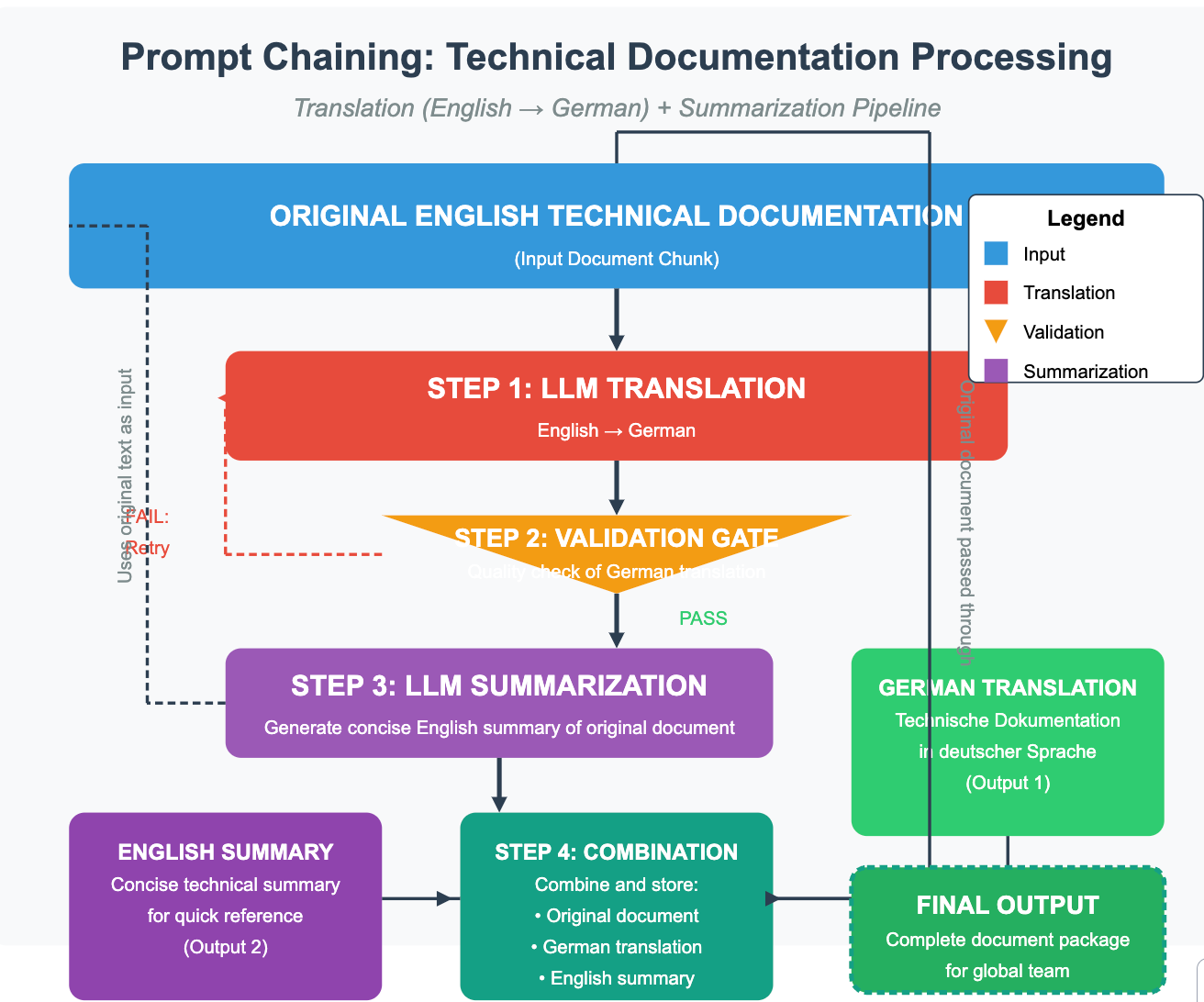
caption...
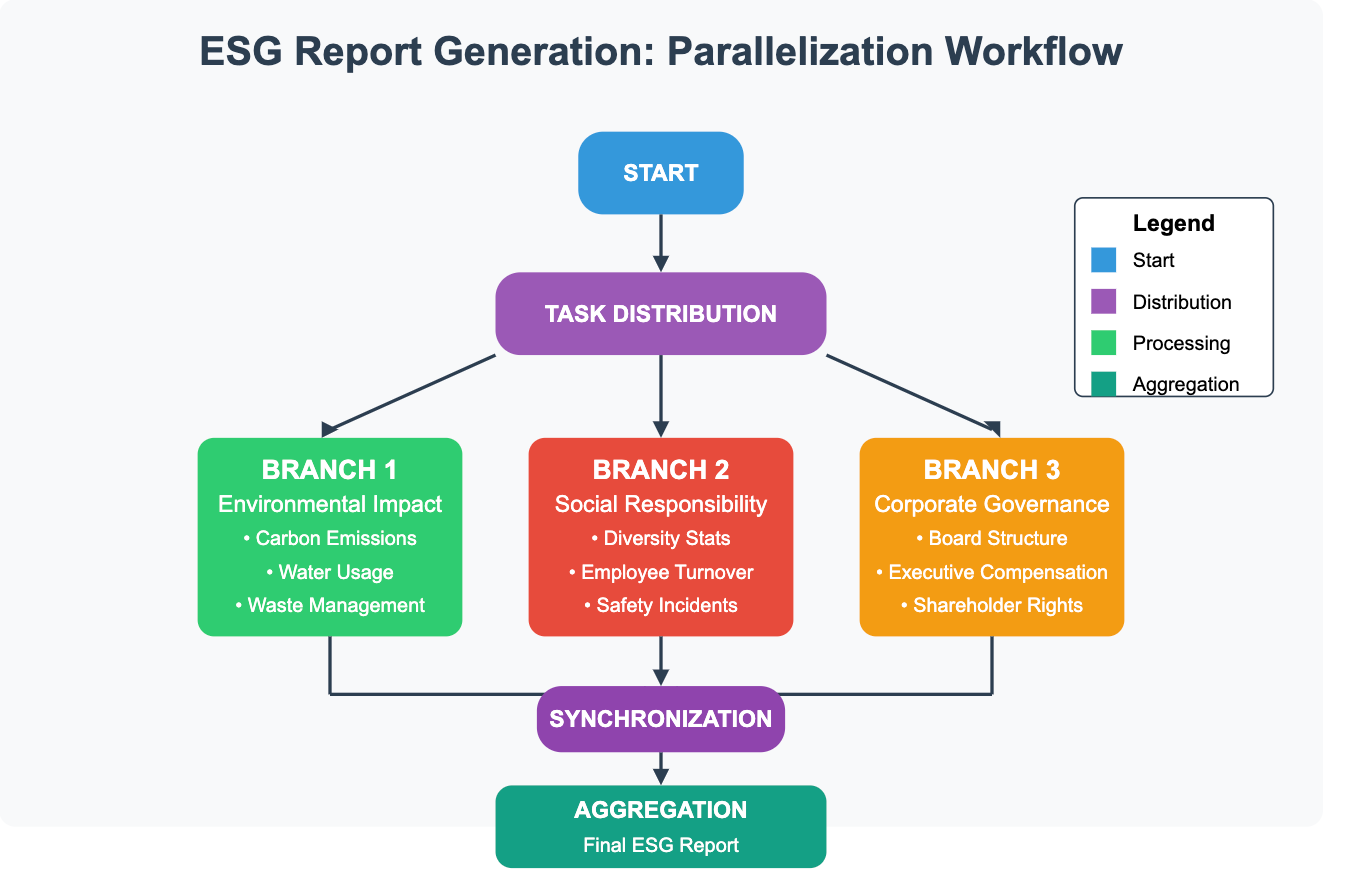
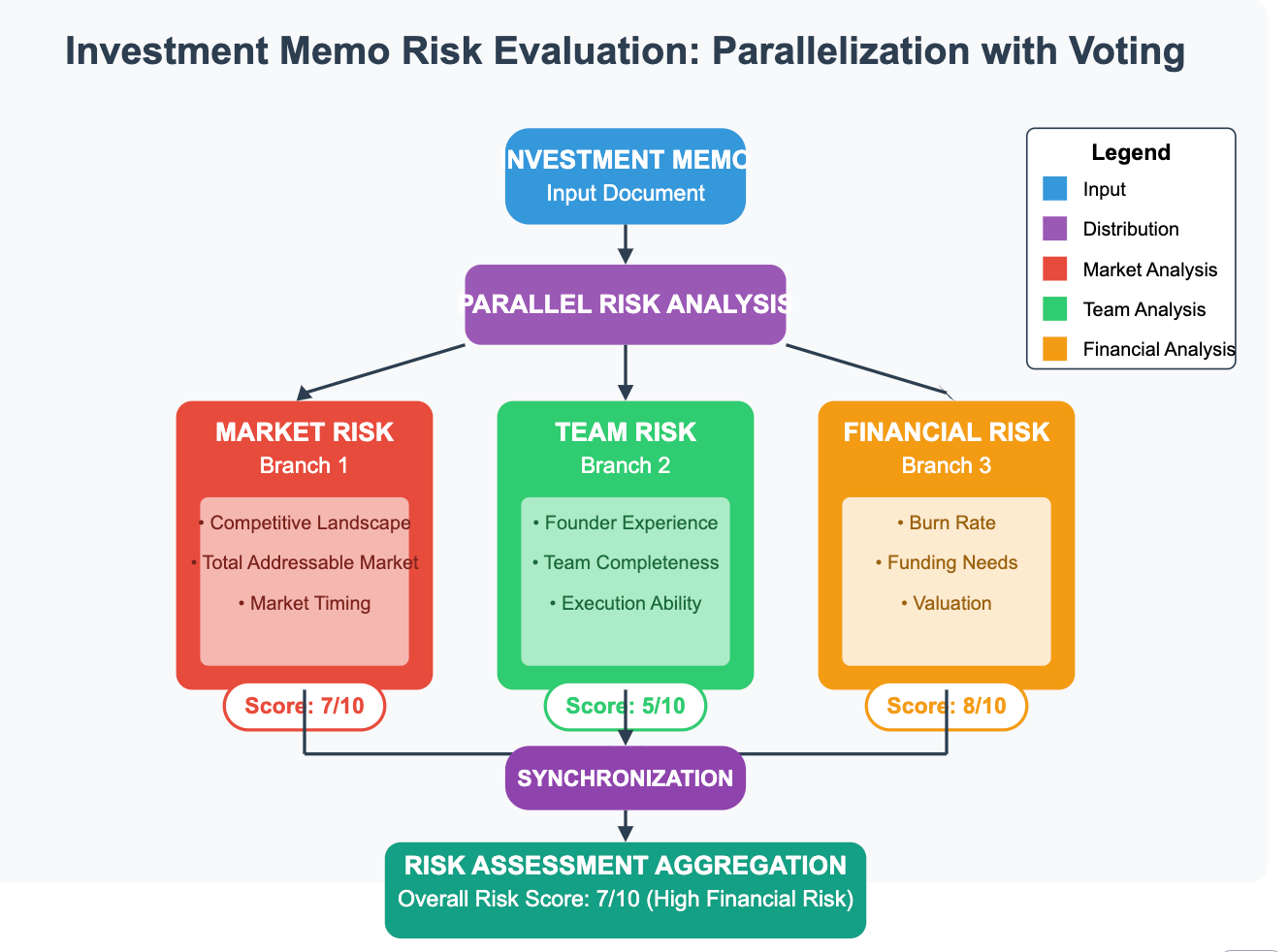
5.2 Parallelization: Concurrent Processing and Synchronization
This involves executing multiple branches or LLM calls concurrently.
Synchronization: A critical technical aspect is the synchronization point. The workflow must wait for all parallel branches to complete before proceeding to the aggregation step. Graph execution frameworks typically handle this implicitly, ensuring all inputs to the aggregation node are available before it executes. Manual implementations require careful use of asynchronous programming constructs (e.g., asyncio in Python, promises in JavaScript) and synchronization primitives.
Aggregation Strategies: Combining results from parallel branches can be technically diverse:
Simple Concatenation: Stringing text results together.
Reduction: Applying a function (e.g., summing numbers, averaging scores, merging lists) across structured outputs.
LLM-based Synthesis: Feeding the outputs of parallel branches as context to another LLM call tasked with synthesizing a coherent final result. This adds latency but can handle more complex merging requirements.
Resource Management: Running multiple LLM calls in parallel can strain API rate limits or computational resources if self-hosting models. Implementing rate limiting, backoff strategies, or resource pooling is often necessary.
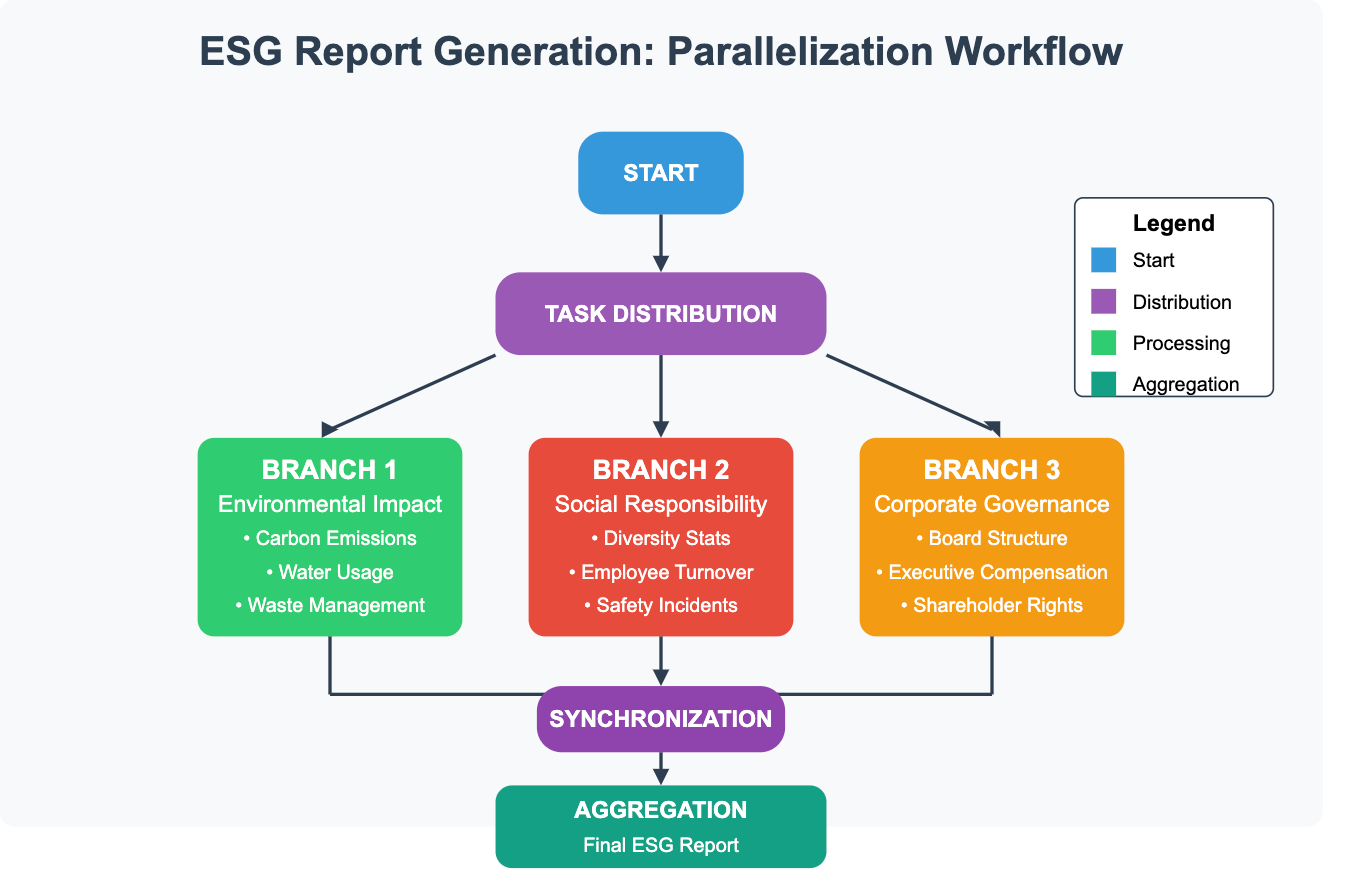
SCENARIO: An investment firm needs to generate an Environmental, Social, and Governance (ESG) report for a portfolio company. This involves analyzing data and drafting sections on environmental impact, labor practices, and corporate governance. These sections are largely independent. Consistency (Voting): When using parallelization for voting or consensus, slight variations in prompts or model non-determinism can lead to divergent outputs. Designing prompts to constrain output format and implementing robust consensus logic (e.g., majority vote, scoring mechanisms) are important

Scenario: A venture capital firm wants an AI assistant to perform an initial risk assessment on investment memos. To increase confidence and catch different types of risks, they want multiple perspectives. .
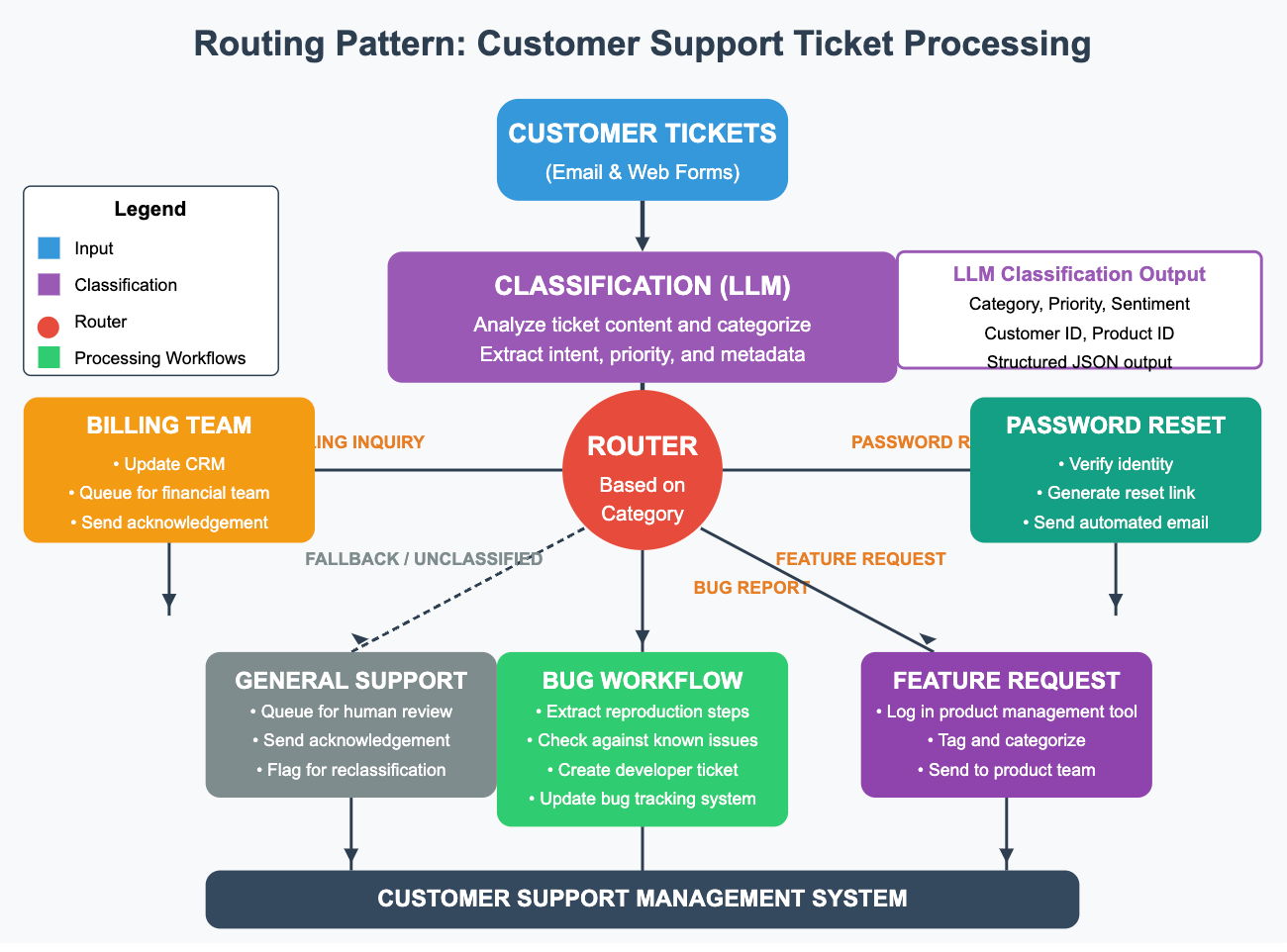
5.3 Routing: Conditional Execution Logic
Routing directs the workflow down one of several predefined paths based on input characteristics or intermediate state.
Classification Mechanism: The core is the classifier deciding the route.
LLM-based Routing: Leveraging function calling or structured output capabilities of modern LLMs to classify the input and specify the next step/node name. Requires careful prompt engineering to ensure the LLM reliably outputs valid routing decisions and handles ambiguity. Can be slower and more expensive than other methods.
Traditional ML Classifiers: Using a separate, fine-tuned model (e.g., BERT, SVM) for classification. Faster and cheaper at inference time but requires training data and maintenance.
Rule-Based Logic: Simple programmatic rules (if/else statements, regex matching). Fast and interpretable but less flexible for complex routing criteria.
Reliability & Fallback: Routing decisions can be uncertain or fail. Implementations need robust fallback mechanisms, such as a default path, requesting clarification, or routing to a human review queue when classification confidence is low or the chosen path encounters errors.
State Transfer: Ensuring the correct subset of the overall state is passed down the selected route is crucial.
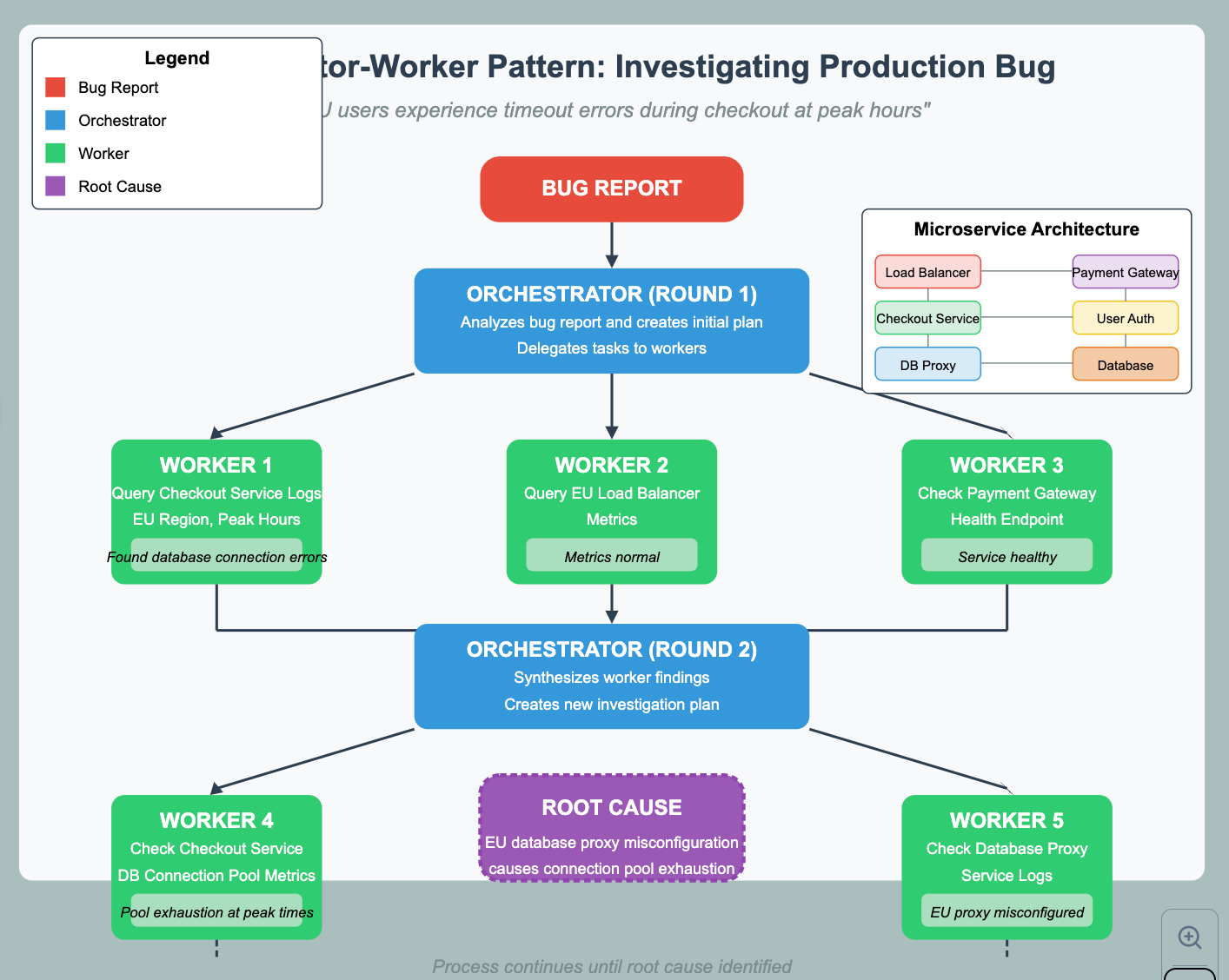
5.4 Orchestrator-Worker: Dynamic Distributed Execution
This pattern dynamically generates and delegates subtasks based on an initial request, typically involving a central orchestrator and multiple workers.
Dynamic Task Generation: The orchestrator LLM must be prompted to output a structured representation of the subtasks (e.g., a list of function calls with parameters, descriptions of tasks for workers). This often involves advanced prompting techniques and relies on the LLM's planning capabilities. Parsing and validating this dynamic plan is a key implementation step.
Worker Communication & State: Managing the execution and state of dynamically spawned workers is complex.
Invocation: Techniques include direct function calls (if workers are local functions), message queues (for distributed workers), or framework-specific mechanisms like LangGraph's Send API, which handles dispatching tasks and data to specified worker nodes.
State: Workers might operate stateless-ly (receiving all necessary context with the task), maintain independent state, or read/write to a shared state repository (requiring careful handling of concurrency and consistency).
Synthesis: The orchestrator (or a dedicated synthesizer node) must aggregate potentially heterogeneous results from workers that may complete at different times. This often requires waiting for all dynamically spawned tasks (or a subset) to finish and then processing their varied outputs, possibly using another LLM call for final synthesis.
Monitoring & Debugging: Tracking the execution flow across a dynamically changing set of workers is challenging. Distributed tracing, centralized logging, and robust status tracking are essential for monitoring and debugging. Scalability can be limited by the orchestrator's planning capacity or bottlenecks in worker execution/communication

Scenario: A bug report comes in for a large microservices-based application: "Users in the EU region sometimes get timeout errors during checkout, especially during peak hours." The specific cause and affected services are unknown. .
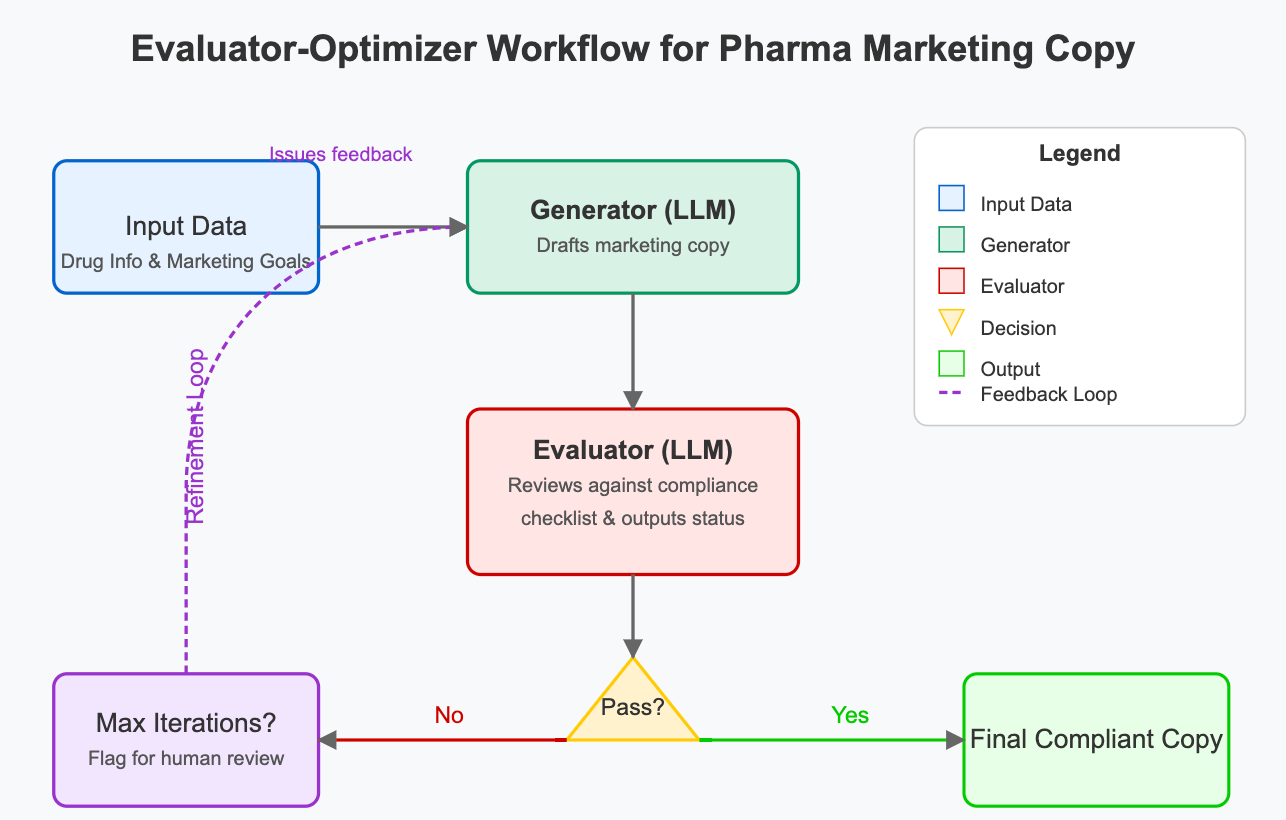
5.5 Evaluator-Optimizer: Closed-Loop Refinement
This involves a generation step followed by an evaluation step, with feedback potentially looping back to refine the generation.
Feedback Integration: The mechanism for incorporating evaluation feedback into the generator's next attempt is critical. This might involve:
Adding feedback directly to the next prompt (e.g., "Improve the previous output based on this critique: [feedback]").
Using feedback to select few-shot examples of successful refinements.
Dynamically modifying the generator's prompt template or parameters.
The effectiveness depends heavily on the generator LLM's ability to understand and act upon the specific feedback provided.
Evaluation Prompting: Designing the evaluator prompt is crucial. It must clearly define the evaluation criteria and specify the desired output format (e.g., a score, a pass/fail grade, structured feedback). The evaluator LLM's consistency and alignment with human judgment on the criteria are key challenges.
Loop Control: Defining clear termination conditions is essential to prevent infinite loops and manage costs. Common strategies include setting a maximum number of iterations, achieving a target evaluation score, or detecting diminishing returns in quality improvement
.
Efficiency Trade-offs: Each iteration involves at least two LLM calls (generator + evaluator), making this pattern potentially slow and expensive. The value proposition hinges on whether the iterative refinement yields significantly better results than a single, more complex generation attempt and whether the evaluation criteria are meaningful and consistently assessable by an LLM.

Scenario: A pharmaceutical company needs to generate marketing copy for a new drug website. The copy must be engaging but also strictly adhere to regulatory guidelines (e.g., fair balance of risks/benefits, no off-label promotion).
6. Understanding AI Agents: Technical Mechanisms and Challenges
Agents introduce LLM-driven autonomy, requiring specific technical enablers and presenting unique challenges.
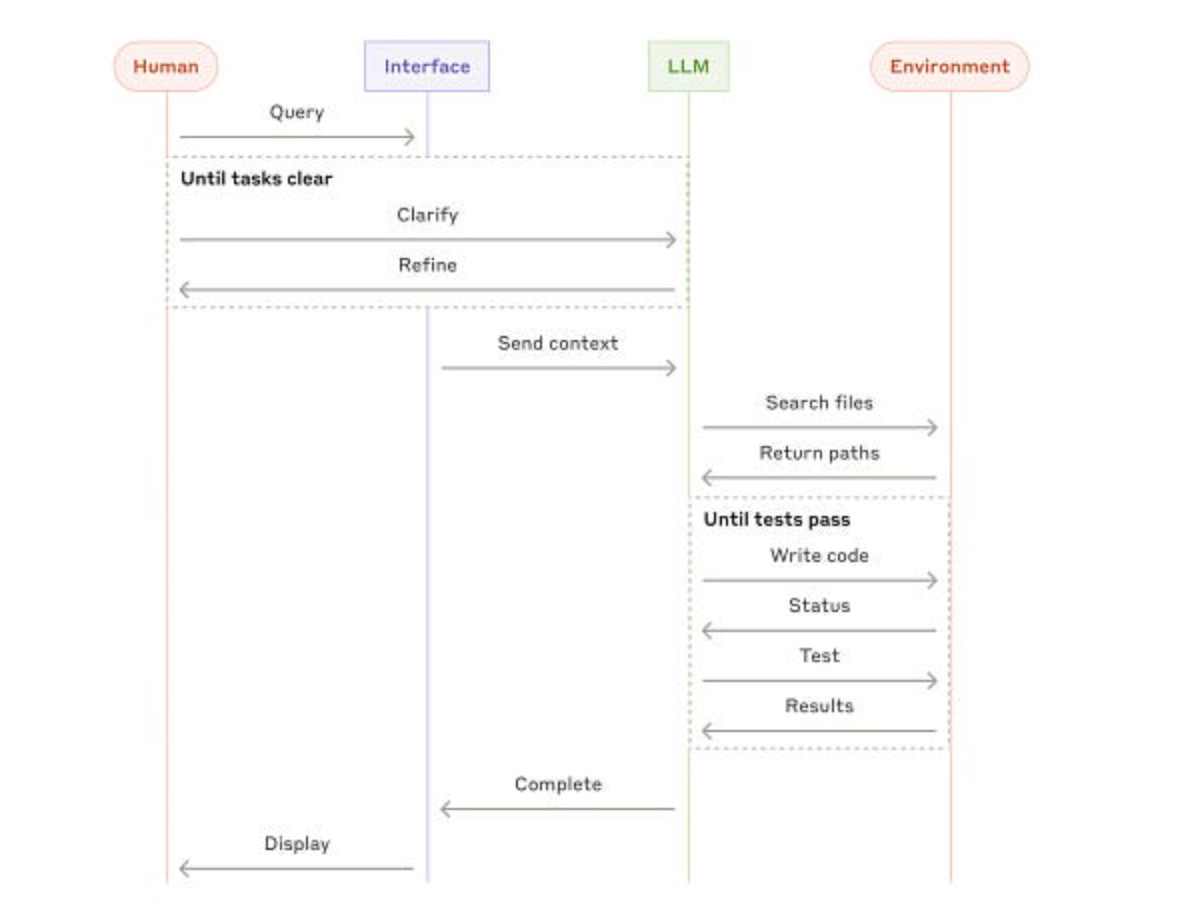
Core Execution Loop: Agent frameworks (executors) manage the Observe -> Think -> Act cycle. Technically, this involves:
State Management: Maintaining the agent's history (past actions, observations, tool outputs) in a "scratchpad" or memory module.
Prompt Assembly: Constructing the prompt for the LLM's "Think" step, including the task, history/memory, and available tools.
LLM Call & Parsing: Invoking the LLM and parsing its response to identify the intended action (e.g., a specific tool call with arguments or a final answer). This often relies on function calling APIs or structured output capabilities.
Action Dispatch: If a tool is chosen, executing the corresponding function/API call.
Observation Formatting: Formatting the result of the action (tool output or error message) for the next iteration's observation.
Tool Use Implementation: This is central to agent capability.
Tool Definition: Tools must be clearly defined for the LLM, typically including a name, description (crucial for the LLM's selection process), and input/output schemas (often using formats like JSON Schema).
Dispatch Logic: The agent executor needs logic to map the LLM's intended tool call (e.g., parsed function name and arguments) to the actual code execution.
API Integration: Tools often wrap external APIs, requiring handling of authentication, network errors, rate limits, and data transformation.
Planning and Reasoning Strategies: Simple ReAct (Reason+Act) agents can struggle with complex tasks. More advanced technical approaches include:
Multi-step Planning: LLM first generates a high-level plan (sequence of steps/tool uses), which is then executed. Examples: Plan-and-Solve.
Reflection/Self-Critique: Incorporating steps where the agent (or another LLM) critiques its past actions or plan and potentially corrects course.
Hierarchical Agents: Using multiple agents, where a "manager" agent decomposes tasks and delegates to "specialist" agents with specific toolsets.
Memory Systems: Beyond the short-term scratchpad, agents may need persistent memory. Technical implementations often involve:
Vector Stores: For retrieving relevant past experiences or knowledge based on semantic similarity. Requires embedding generation and retrieval logic.
Summarization: Techniques to condense growing history to stay within context limits.
Robustness and Error Handling: Agents are prone to various failures:
Malformed Tool Inputs: LLM generates arguments that don't match the tool schema. Requires input validation before execution.
Tool Execution Errors: The tool itself fails (e.g., API unavailable, code bug). Requires try-except blocks and informative error messages fed back to the agent.
Hallucinated Tool Calls: LLM attempts to call non-existent tools. Requires strict parsing against the available tool list.
Looping Behavior: Agent gets stuck repeating the same actions. Requires loop detection, limiting iterations, or changing prompting strategy. Robust error handling might involve fallback tools, asking for clarification, or escalating to human intervention.
Context Window Management: The agent's interaction history (observations, thoughts, actions, tool results) must be carefully managed to fit the LLM's context window. This often involves truncation, summarization strategies, or more sophisticated retrieval methods to surface only the most relevant parts of the history for the current decision-making step. This is a critical bottleneck for long-running agents.

Agent Definition | Credits: Anthropic 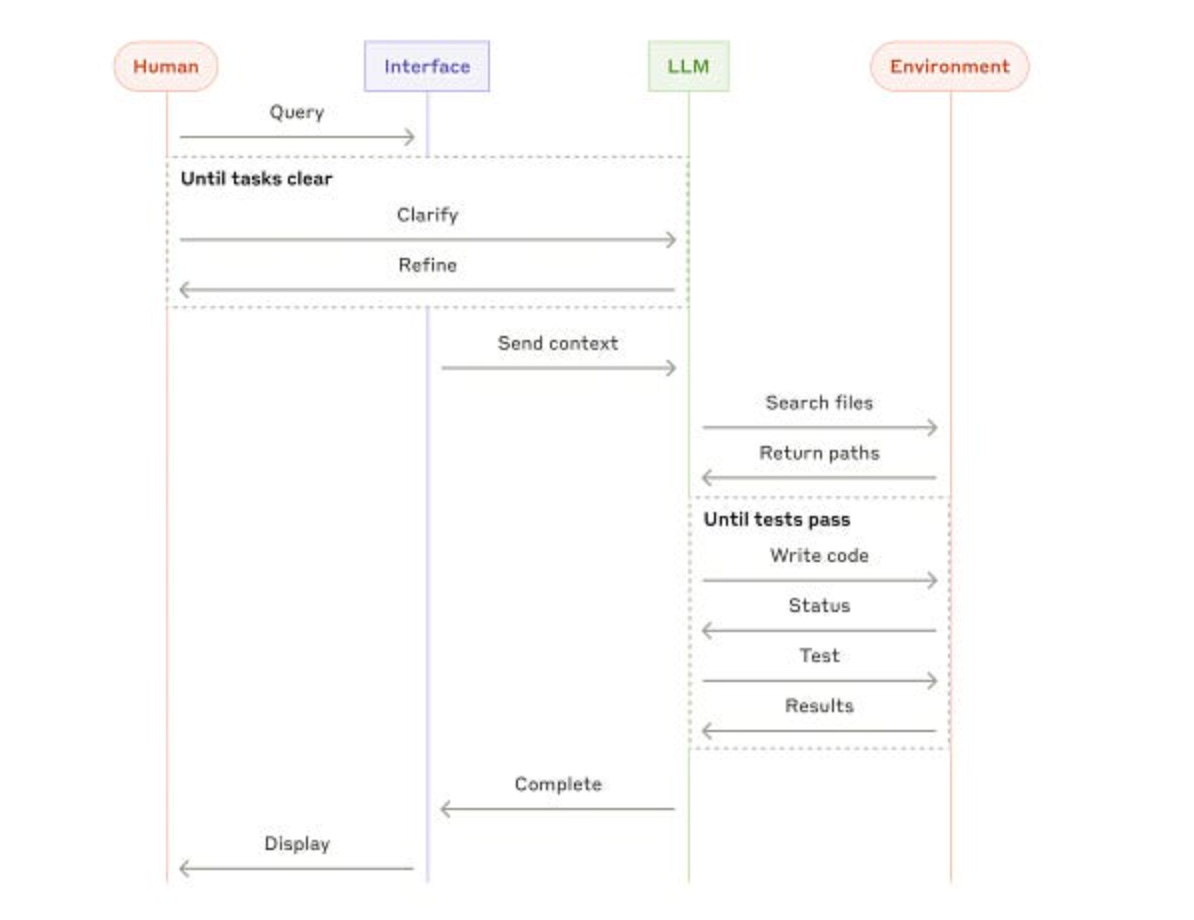
High-level flow of a coding agent | Credits: Anthropic
7. Combining Forces: Integrating Workflows and Agents
Often, the most powerful solutions blend structured workflows with dynamic agents. A predictable workflow can handle the overall process, while calling upon an agent to manage specific sub-tasks that require flexibility and autonomous decision-making.
Example: A document processing workflow might handle ingestion, classification (routing), and storage, but call an agent equipped with research tools to dynamically find and incorporate missing information for certain document types before final processing.
This hybrid approach balances predictability with adaptability, leveraging the strengths of both paradigms.
8. Conclusion: Building Appropriately Complex Systems
The goal isn't necessarily to build the most complex agent possible, but the most appropriate system for the task. Effective AI system design prioritizes clarity, reliability, and maintainability.
Key principles include:
Start Simple: Always explore simpler solutions (optimized prompts, basic workflows) first.
Justify Complexity: Only introduce more complex workflows or agents when simpler approaches are insufficient and the benefits clearly outweigh the costs.
Focus on Interfaces: Especially for agents, pay meticulous attention to tool design, documentation, and error handling.
Modularity: Build systems from well-defined, understandable components, whether they are steps in a workflow or tools for an agent.
By understanding the fundamental differences between workflows and agents, and the patterns available within each, developers can make informed decisions to build AI systems that are both powerful and practical.